


"Competitor-obsessed startups rarely win. Customer-obsessed startups always win." Exotel's Voice Platform handles millions of calls per day, among which 35% of total calls are recorded and uploaded to the cloud for long-term storage and customer access. In the current age of data, call recordings are...
“The problem with digital architecture”, says Peter Eisenman, “is that an algorithm can produce endless variations, so an architect has many choices”. This statement equally rings true when designing modern distributed systems that require careful thought and in-depth analysis before design decisions are made.
A lot has been said about Go’s context library, and its use in pipelined processing for HTTP request-response. There are use cases where the context library can be an off-the-shelf solution to maintaining context flow. However, how does Go’s context library help in designing other highly concurrent and distributed system? What is the code complexity when using Golang contexts for intra-process context management? These are some of the answers we shall try to seek here.
Go’s Context Library
Let us begin by understanding what context is. The dictionary defines “context” as “The circumstances that form the setting for an event, statement, or idea, and in terms of which it can be fully understood”. In abstract machines, this simply means correlating events occurring within the system on the time axis. An event or a trigger occurring at a point in time is correlated with another event or trigger occurring at a different point in time if they refer to the same underlying flow. An example would be a call established between two parties. The call is the context while events define what state the call is in at any given point in time.
Go helps build context-aware systems by providing a context library, which internally manages multiple contexts within a system in the form of a tree. There are various kinds of context nodes, so let us enumerate them:
-
- Background Node: This is the root node of a context tree. This is an empty context node and has no further information.
- Value Node: A node of this type is created using the WithValue() function. Value Node is a new context node that is derived from a parent node, and additionally has a key and an optional value stored in the node.
- Cancellable Node: This node is also derived from a parent node, except that these it contains a Done channel. This Done channel signals the end of the relevance of the context subtree rooted at this node. Therefore, all descendent nodes should clean up resources when this signal is received at the ancestor node. Cancellable nodes have a cancel function; with or without a deadline or timeout value. The respective calls are WithCancel(), WithDeadline() and WithTimeout(). Deadline takes an absolute time when the context expires. Timeout takes the delta duration from current time for context expiry. Done channel is closed automatically when time limit is reached. It may also be cancelled explicitly before time limit exert by invoking the cancel function.
- TODO() Node: These context nodes are more for future support of context in legacy code, therefore, we shall not bother about them much here.
Illustrating with an example: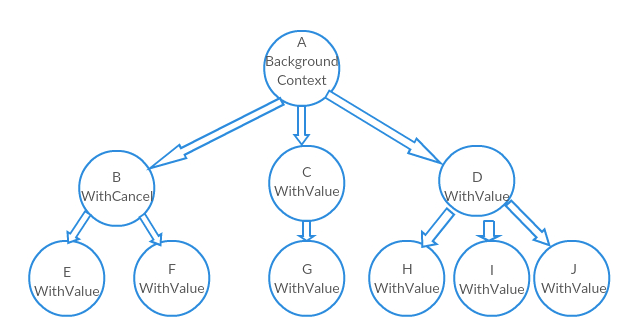
A = context.Background()
B = context.WithCancel(A)
C = context.WithValue(A, “Value”, “C”)
D = context.WithValue(A, “Value”, “D”)
E = context.WithValue(B, “B Key”, “E”)
..
H = context.WithValue(D, “D Key”, “H”)
..
It is extremely important to note that the original nodes are themselves not modified. Instead, a new copy of the input parents nodes are returned.
Cancel nodes don’t have any key information stored within them and are used for their Done() channel alone. When a node is added in the context tree, it is added to the map of every cancellable parent or an ancestor node. Hence, when a parent (or ancestor) node invokes a Done(), the child’s Done() channel is also closed, and the child is removed from the map of this ancestor.
Cancellation signals are perfectly safe when used by multiple simultaneous routines. The Done() call acts only the very first time in propagating the signal. Context Err parameter is set to indicate the reason for closing the Done() channel. Subsequent Done() calls are no-ops because of a non-nil Err parameter.
One powerful feature of Context library: they are safe for use by multiple goroutines working on them simultaneously (as documented in the blog). How is this achieved? A look at the implementation gives us the reason. Value nodes are read-only. Once a value node is formed, they can be read out on the basis of the key. Therefore, the message is very clear: value in context nodes are non-mutable, or must be lock protected by goroutines trying to change them. They are not variable parameters but are identifiers to the context nodes themselves.
Go Context And Finite State Machines (FSM)
As in our example of a call between two parties, the flow of events in the system can be characterised as an abstract state machine. The state machine has a well-defined start state (say, when the calling party requests a call by dialing the destination number). It also has a well-defined end state (when the two parties have hung up and resources corresponding to the call are released). As is evident, there is one FSM instance corresponding to every such call. Therefore, every call has a context of its own.
In a cloud telephony system, the central intelligence is built around an FSM with well-defined states and rules that govern state transitions based on events occurring within the context of the telephony service. Events in a call, for example, might include a user dialing out a number, hanging up, call being dropped due to capacity reasons, and the like.
Go’s context library seems to be a good fit in context management of multi-instance state machine based system. Each incoming call request is handled in its own goroutine. Each call triggers database operations, authorisation services, and other distributed services like lock management services. While it is indeed tempting to start using the context library, however, once one’s hands are dirtied, one also come across the pitfalls.
Let us now examine points where the library may spring up a few surprise gotchas.
Points to Keep In Mind When Evaluating Use of Go Context:
-
- Code Complexity: Using Context Library to do context management can very easily complicate the code. Therefore, identifying the exact use case becomes imperative. Going back to a telephony system, there might be different context tree that need to be built depending on the hardware interfaces, each of which might handle multiple simultaneous call contexts. Therefore, the process context tree can very easily bloat up for complex scenarios. Memory footprint increases, therefore memory management comes into play (also see the point on garbage collection).
- Node Traversal Inconveniences: Another point to keep in mind is that traversal between various nodes in a context tree is not available. Like stated earlier, there are no pointers from the parent node to children nodes. Therefore, the correct context node should be read out for a particular key value. This introduces the need for storing the right context for lookup, which is very inconvenient especially if the context tree starts growing deeper. In such flows, it is easier to have sync Mutex implemented within a structure than using the context library. An in-memory map can be used to store the (key, value) pair of the context flow and be protected by a global lock (or a very similar gorilla context may be evaluated for use). Additionally, goroutines requiring access to the same data first acquire a key-level lock and then get to manipulate data. An RWMutex is especially useful where the number of readers might far exceed the writers.
- Garbage Collection: GC occurs when a particular context node is dereferenced. So when exactly are context nodes dereferenced? Unfortunately, since there are no front or back pointers like in the case of a conventional tree, GC of a context occurs when it goes out of scope. There are no explicit functions that can be invoked to clean up a context tree. One has to design the flow in such a way that a context node is no longer relevant when the goroutine which created it, exits. Therefore, the node goes out of scope as soon as the routine exists. Persisting context node will never clean up the context.
- Passing Signals Between Nodes: Done channel cannot be shared between processes or nodes. So then, how should the cancel signal be propagated downstream? There seems no easy way to do so. Two approaches may be possible. The first is to design the pipeline in such a way that individual processes handle timeouts and cancel conditions independently. The second, more complicated, approach will be to have a cancel RPC that will be invoked when a request has to be cleaned up downstream. This RPC may issue a channel that is caught by the requesting goroutine, leading to cancellation and cleanup of the request. Again, looks like it is not a straightforward approach.
Conclusion
There isn’t tremendous amount of documentation explaining the where and where not to use Go context library. Though it is advertised primarily for requests spanning multiple processes and APIs, its use in other less-documented cases needs some investigation. Care needs to be taken to ensure that it fits the design requirements. Hope this blog helps clarify a few points to look out for when starting off with the library.
Questions? Comments? We’d love to hear from you!


 +91-8088919888
+91-8088919888 +61-2-8073-0559
+61-2-8073-0559 +62-215-098-4960
+62-215-098-4960 +60-3-2771-2799
+60-3-2771-2799 +65-6951-5460
+65-6951-5460