


"Competitor-obsessed startups rarely win. Customer-obsessed startups always win." Exotel's Voice Platform handles millions of calls per day, among which 35% of total calls are recorded and uploaded to the cloud for long-term storage and customer access. In the current age of data, call recordings are...
We have been growing faster than ever and that has brought us interesting and challenging tech problems. Compared to last year, there has been a 5X increase in the number of calls and a 4x increase in the number of SMS-es per day. While the “problem of scale” is what we have been tackling with design and architectural changes, it also means more and more businesses are relying on Exotel’s uptime.
No Single Point of Failure
One of our design goals has always been to ensure there is no single point of failure. While we redesign, rewrite and re-architect, one of our Achilles heels has been flaky Internet. We are a cloud telephony company and we have two types of servers — the telephony servers which host your telephone lines and the “control” servers which tell these telephony servers what to do. The latter is where all the configurations that you created using the App Bazaar reside. The telephony servers reside in secure datacenters in Chennai, Bengaluru, Delhi and other Indian cities we operate in while the control servers reside on the Amazon Cloud(AWS). During a call or an SMS, the telephony server and the “control” server talks multiple times. This interaction happens over the internet. If the internet connection between the two servers goes down or even if there is a 10% drop in packets, the call logic would be broken and the telephony server will not know what to do next with the call. Such a situation is annoying to us and more to a customer.
As someone said “Many Paths lead to Rome.”
Last week we did some changes to greatly reduce such downtimes. One observation that we had was that the path taken by packets from different telephony servers to our servers in AWS were vastly different. Different ISP paths take different routes. Even when the internet connection between the AWS servers and the server in Bangalore was down, the AWS servers were very much reachable from other servers, like Chennai, Hyderabad etc. Also, the Bangalore server had solid connections with the other telephony servers. This made us think why not route the traffic via these servers to the AWS servers, when this happened.
HAProxy and Squid Proxy to the rescue
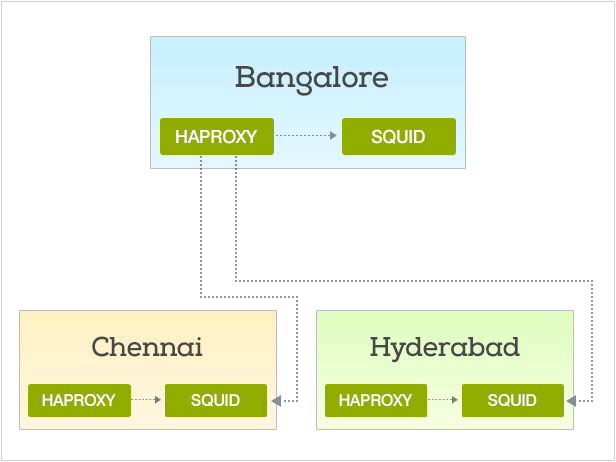
We built a backup network using HAProxy and Squid Proxy, and this is how. On every telephone server, we installed both HAProxy and Squid Proxy. HAProxy is a load balancer and Squid is a Forward Proxy that talks to the AWS servers. To the HA Proxy, we add the Squid Proxy installed on that server as the main proxy and every other Squid Proxy installed on other telephone servers as a backup proxy. We configured HA proxy to try pinging an HTTP endpoint via each of the Squid Proxies connected to it. This is to calibrate which of the servers are healthy. If the main proxy on the local server is unhealthy, it will automatically route the request via the most healthy backup server.
Let’s say we have Bangalore server and its backup server is the Delhi and Chennai servers. By default, HAProxy will send the request to local(Bangalore) Squid Proxy which will make the connection to our AWS servers. When the internet connection between the Bangalore server and the AWS servers becomes flaky, the health check will fail. When the this happens, HAProxy will stop sending requests to the Local(Bangalore) Squid and it will send via the Chennai or Delhi Server whichever is the most healthy.
This has vastly reduced our downtimes due to bad Internet. However well you design your stack, bad internet can make all of it irrelevant. It is better to plan for that too. If you have tackled this differently, do drop in a comment. It would be good to exchange notes.


 +91-8088919888
+91-8088919888 +61-2-8073-0559
+61-2-8073-0559 +62-215-098-4960
+62-215-098-4960 +60-3-2771-2799
+60-3-2771-2799 +65-6951-5460
+65-6951-5460